First, this page will explain the effectiveness and benefits of our model, with examples from live RetentionEngines. Then, I will explain how the RetentionEngine determines which cancel resolution is shown to the customer, and how it self optimizes. Cancel resolutions are both conditional and predictive.
Note: For Discount cancel resolutions, there is customer context that is used to determine whether or not the resolution should be shown to the customer. That will not be discussed on this page.
Benefits To Our Method
1. Our Model Improves Quickly, Without Manual Work
On an e-commerce company's first day with RetentionEngine, they saved ~11% of customers.
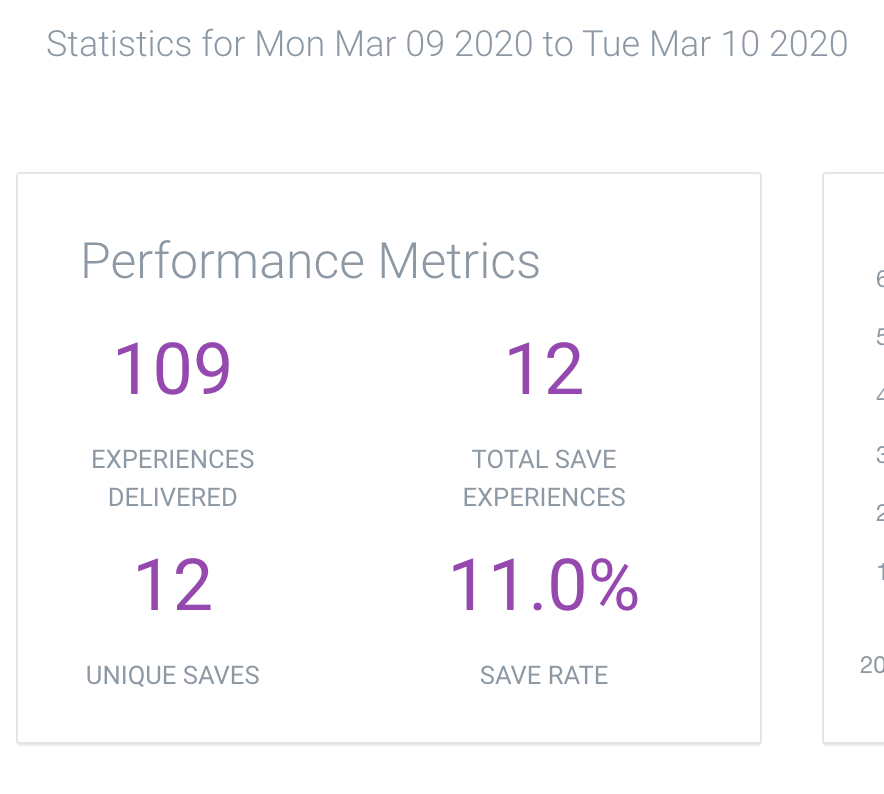
Our model uses each cancelation experience to learn and make a better decision in the future. Just 7 days later, they saved ~23% of customers, WITHOUT DOING ANYTHING DIFFERENT. 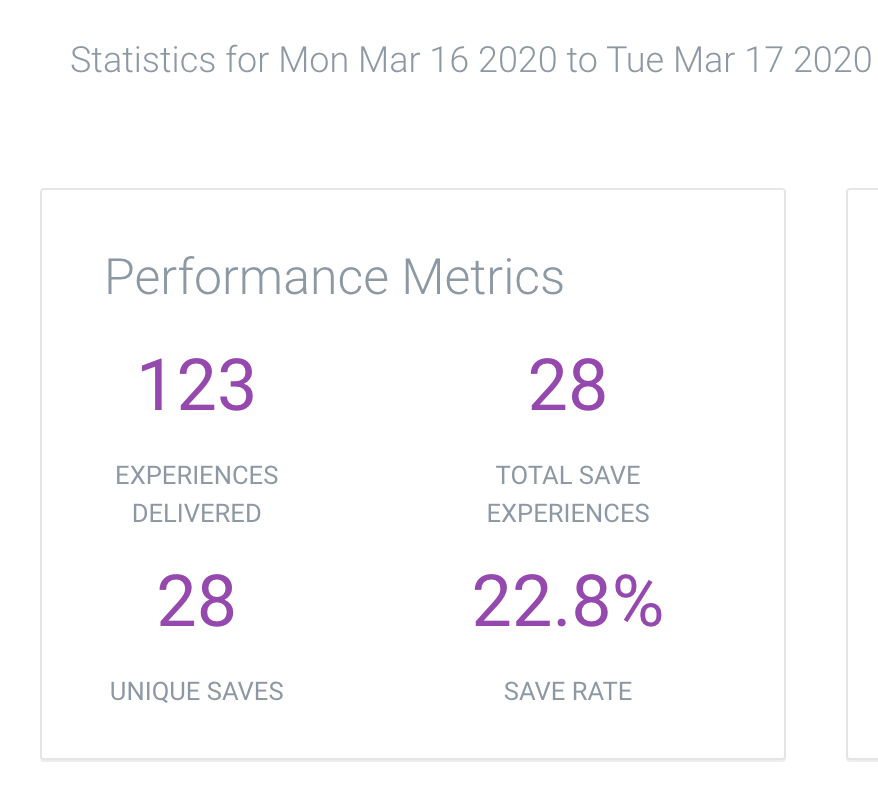
2. Our Model Figures Out What Is Effective At Saving Customers
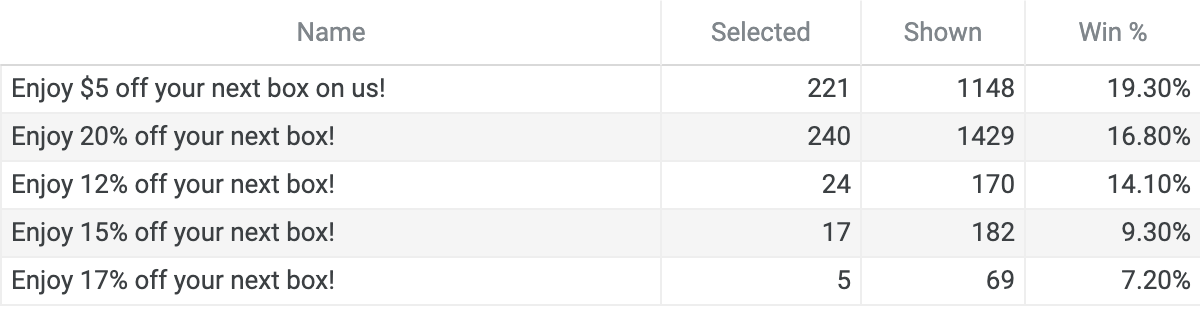
In this chart, "Shown" is the number of times a customer saw that cancel resolution, and "Selected" is the number of times the resolution was claimed or successful. The RetentionEngine is like a laboratory for testing cancel resolutions. In the beginning, you can just start by throwing in 3-5 different resolutions and see what happens. Who would have ever guessed that a 12% discount would outperform a 15% discount?
After a while, you can deactivate cancel resolutions that aren't performing well, and iterate on the ones that are. For example, none of these resolutions uses an image. If we showcased a sneak peek of next month's box with an image, would that significantly improve the $5 discount? What if we tried a 22% discount, it's only slightly higher than 20%, but it could have a significantly higher win %.
Now, let's talk about how we get these results. Here's how our model decides what resolution to show.

Step 1: Assign Conditional Logic to Exit Survey
Let's say a customer has selected in the exit survey "It's too expensive."
RetentionEngine will now need to decide which cancel resolution to show. This will be determined based off of the cancel resolutions you have assigned to this exit survey response.
When creating a cancel resolution you can select which exit survey responses you would like it linked to. This means that our algorithm will only predict based on your narrowed set of cancel resolutions for each exit survey response.

Because sometimes there are cancel resolutions that may be illogical to show for certain exit survey responses (ie a discount after a customer has indicated they are having technical difficulties).
Step 2: Select a Random Probability For Each Cancel Resolution
Now that the cancel resolutions have been narrowed down for each reason, our algorithm selects a random probability for each cancel resolution.
When we say random, some numbers are more random than others. I know... but just buckle your seatbelt and hold on. I’ve got tables & graphs. The random number selected is from a distribution tied to the past performance of said cancel resolution, and how many times it’s been shown. This is a machine learning technique called Thompson Sampling. It allows the model to have a healthy rate of exploration versus exploitation. It also allows the model to learn and improve quickly.
For example, consider the three cancel resolutions below, where selected is the number of times a cancel resolution has retained a customer. Notice that all of the offers have the same success rate.

Now, let's look at the probability distributions of each of the offers. Notice that Cancel Resolution 3 is extremely narrow, as opposed to Cancel Resolution 1. So, if I randomly choose a point under the blue curve, I am likely to get a probability between 0.2 and 0.26 (the x coordinate of the point). But, if I randomly choose a point under the red curve, the range is much wider and I am likely to end up with a number anywhere from 0.15 to 0.58.

The range of possible random probabilities is from 0 to 1, BUT some probabilities are more probable than others. As the number of times a cancel resolution is shown increases, the distribution graph becomes narrower, so the random probability selected will be close to the actual win percentage. When the distributions are wide, especially in the beginning, the probabilities selected are extremely scattered which allows for exploration when the success of a cancel resolution is relatively unknown.
I selected a random number based off of these specific cancel resolution and ended up with the following results:
- Cancel Resolution 1: 0.37084796752
- Cancel Resolution 2: 0.24660744682
- Cancel Resolution 3: 0.234863075841
Thus, Cancel Resolution 1 is shown to the customer.
Step 3: Update the Win Percentage
The win percentage is updated on the cancel resolution shown based on whether it was successful or not, i.e., did the customer cancel or were they retained.
Hence, every experience trains the model and the distributions are adjusted to make a better decision for the next experience. But in the beginning, when the distributions are wide, the probability for exploration is higher.
Because of this randomness, there will always be some exploration in the RetentionEngine. Even more, every experience updates the performance of each cancel resolution. So, if a cancel resolution begins performing poorly, it will become less likely to show in the future.
There is never a point that the RetentionEngine decides to stop showing a cancel resolution to customers. (Unless, of course, you set it to inactive.) But eventually, it becomes extremely unlikely for certain offers to be shown to customers after they’ve proven themselves to be ineffective.
What happens when you add a new cancel resolution?
After a while, you will want to iterate and improve on the initial cancel resolutions that you’ve created. (We recommend iterating about every 1000 experiences for the first few months with RetentionEngine.) When you create a new cancel resolution, it will slowly be thrown into the mix. (If you want to give it a headstart, you can temporarily disable your highest performing cancel resolutions.)
For example, if you introduce a new cancel resolution amongst the following cancel resolutions, the probability distributions look like this.

After a few experiences with the new cancel resolution being shown (and the following outcomes) -

The updated distribution of the new cancel resolution looks like this. Notice how the new Cancel Resolution (#4) begins taking shape.

‼️ Be careful editing cancel resolutions.
If you are making significant changes to a cancel resolution, such as changing the image or description, then we recommend creating a new cancel resolution. Unless you know the changes will not affect the performance of the cancel resolution, we recommend only editing cancel resolutions with small changes such as typos.